Kafka实践
原理
linkedin开发,Scala语言
Topic & Partition
Topic 在逻辑上可以被认为是一个 queue,生产者必须指定消息的 Topic,可以简单理解为必须指明把这条消息放进哪个 queue 里。为了使得 Kafka 的吞吐率可以线性提高,物理上把 Topic 分成一个或多个 Partition,每个 Partition 在物理上对应一个文件夹,该文件夹下存储这个 Partition 的所有消息和索引文件。segment为实际存储消息的文件(大小一致),分为index(消息在log中的偏移量)和log(具体消息,包含一定的管理结构),将一个大的partition进行分拆,方便资源回收。 topic:partition ==> 1 : N partition : segment => 1 : N segment => index + log
Kafka 只会保证在 Partition 内消息是有序的,而不管全局的情况。
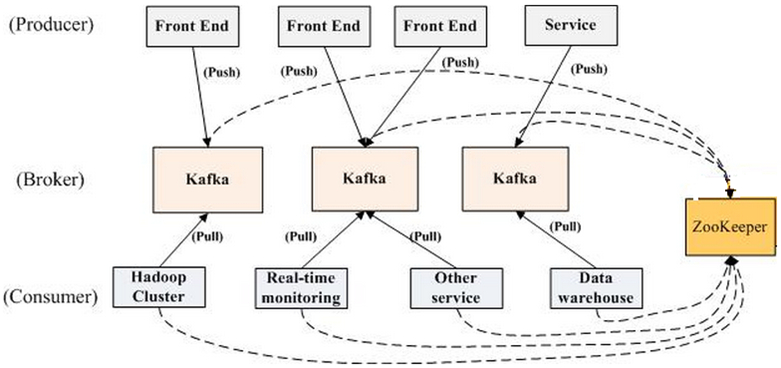
Producer 消息路由
Producer 发送消息到 broker 时,会根据 Paritition 机制选择将其存储到哪一个 Partition。如果 Partition 机制设置合理,所有消息可以均匀分布到不同的 Partition 里,这样就实现了负载均衡。如果一个 Topic 对应一个文件,那这个文件所在的机器 I/O 将会成为这个 Topic 的性能瓶颈,而有了 Partition 后,不同的消息可以并行写入不同 broker 的不同 Partition 里,极大的提高了吞吐率。可以在 $KAFKA_HOME/config/server.properties 中通过配置项 num.partitions 来指定新建 Topic 的默认 Partition 数量,也可在创建 Topic 时通过参数指定,同时也可以在 Topic 创建之后通过 Kafka 提供的工具修改。
Consumer Group
同一 Topic 的一条消息只能被同一个 Consumer Group 内的一个 Consumer 消费,但多个 Consumer Group 可同时消费这一消息,既一个 Topic 可以对应多个 Consumer Group。
Kafka 而言,pull 模式更合适。pull 模式可简化 broker 的设计,Consumer 可自主控制消费消息的速率,同时 Consumer 可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
传输可靠性保证: producer:(默认producer.type=sync,也可以设置为async,此时批量发送,性能提升,但可靠性降低) 通过request.required.acks参数设置数据可靠性级别: - 1:默认,leader成功接收并确认,leader宕机会丢失; - 0:无需等待确认,传输效率高,可靠性低; - -1,all:等到所有follower确认,可靠性高,效率低;配合副本数,控制整体可靠性;
- At most once 消息可能会丢,但绝不会重复传输
- At least one 消息绝不会丢,但可能会重复传输
- Exactly once 每条消息肯定会被传输一次且仅传输一次,很多时候这是用户所想要的。
存储可靠性:
多副本!(Leader+Follower),follower定期复制leader数据。会影响吞吐率。每个partition有一个唯一的leader。所以这里的leader,follower是partition(实际存储的物理单元)维度的! 消息提交之后采备复制到副本。
- AR:Assigned Replicas,所有的副本。=ISR+OSR
- ISR:In Sync Replicas,副本同步队列,leader负责维护并跟踪!记录的是leader+follower的同步信息;
- OSR:Outof Sync Replicas,从ISR移出的follwer;
- HW:HighWatermark,consumer能够看到的partition的位置;每个副本都有维护HW(避免leader失效导致HW丢失),取ISR中最小的LEO值(短板);
- LEO:LogEndOffset,partition log最后一条message的位置;
Leader:
当ISR中的个副本的LEO不一致时,如果此时leader挂掉,选举新的leader时并不是按照LEO的高低进行选举,而是按照ISR中的顺序选举。
消息去重:
使用guid,broker尚无该模块,最多保证at least once,需由业务自身保证。
并发处理:
多个consumer同时消费的话,如果只有一个partition,则实际只有一个工作。 实际并发数收到partition数量的控制。
- a、一个partition就是一个存储kafka-log的目录。
- b、一个partition只能寄宿在一个broker上。
- c、单个partition是可以实现消息的顺序写入的。
- d、一个partition,只能被消费组里的一个消费者消费,但是可以同时被多个消费组消费,优化:只被单个进程消费
- e、单个消费者进程可同时消费多个partition,即partition限制了消费端的并发能力。
- f、partition越多则file和memory消耗越大,要在服务器承受服务器设置。
- g、每个partition信息都存在所有的zk节点中。
- h、partition越多则失败选举耗时越长。
- k、offset是对每个partition而言的,partition越多,查询offset就越耗时。
- i、partition的数量是可以动态增加的(只能加不能减)。
常用操作
topic创建及查看
./bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server 10.194.xxx:9095
./bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server 10.194.xxx:9095
./bin/kafka-topics.sh --list --bootstrap-server 10.194.106.61:9095
消息生产及消费
bin/kafka-console-producer.sh --topic quickstart-events --broker-list 10.150.xxx:9095
bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server
消息查看
bin/kafka-console-consumer.sh –bootstrap-server 10.194.106.61:9095 –from-beginning –topic test
读取指定位置消息
./kafka-console-consumer.sh --topic xxx --bootstrap-server xxx:9092 \
--property print.key=true \
--property key.separator="-" \
--partition 0 \
--offset 156303363 \
--max-messages 2